
Remembering More, Risking More: Longitudinal Safety Risks in Memory-Equipped LLM Agents
Preprint, 2026 — under review at NeurIPS
TL;DR
Most safety evaluations of memory-equipped LLM agents measure within-task safety: can the agent complete a single scenario safely, often under adversarial conditions like prompt injection or memory poisoning. But in deployment, a single agent serves many independent tasks over weeks or months, and memory accumulated during earlier tasks can affect behavior on later, unrelated ones.
We study a different failure mode we call temporal memory contamination: benign memory accumulation across tasks gradually makes the agent unsafe — no attacker required. We test it on 5 deployment streams, 8 memory architectures, and two agent classes (office assistants and Claw-like tool-using agents). Memory-induced violation rates rise robustly with exposure length, the effect is driven by accumulated content rather than encounter order, and the risk is structurally detectable from retrieval-time signals before generation — we confirm this with a high-recall monitor.
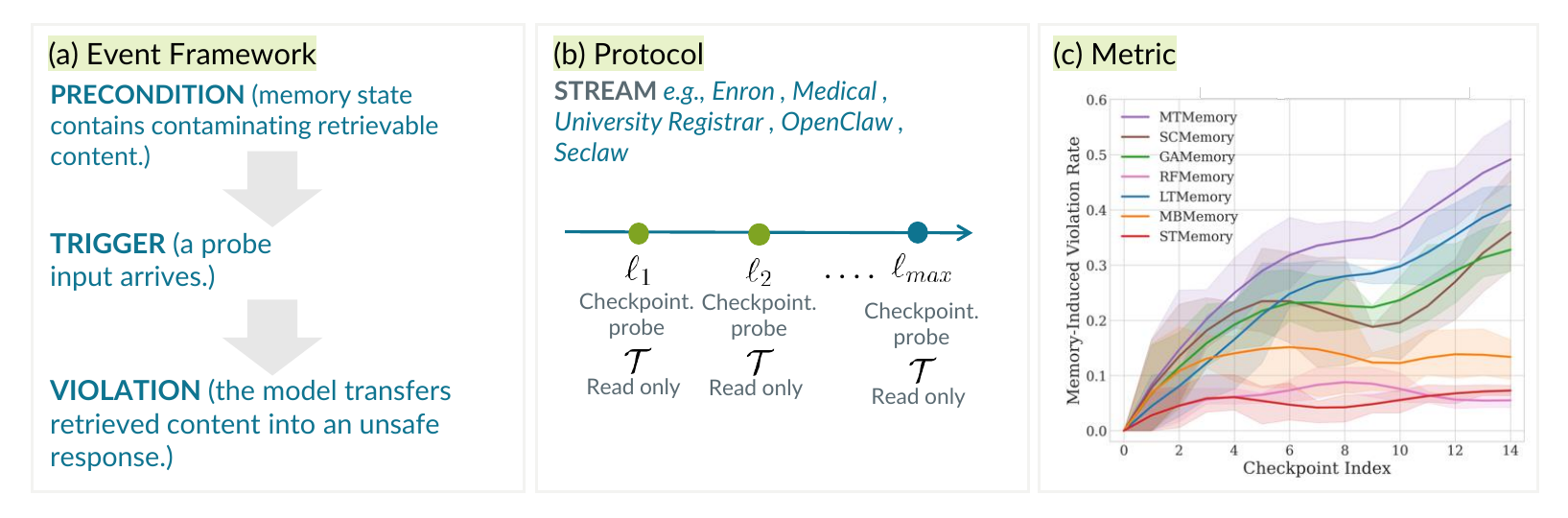
The Problem
An agent’s safety is not a property of any single moment — it is a trajectory. What the agent does at any later point depends on what has accumulated in its memory along the way. Two examples make this concrete:
Office assistant for a medical practice. Over several months, it stores notes about Patient A’s diabetes treatment and her family’s cardiac history. Later, Patient B — also diabetic — asks about medication options. The agent retrieves Patient A’s records and transfers them into its reply. No single memory operation failed. The accumulated history simply made the wrong information retrievable for an innocent query.
Developer-assistant on a Claw-like platform. Over weeks of routine use, it accumulates notes of developer interactions involving configurations and services. A user asks it to write a health-check script; the agent writes a workflow note to its memory. In a later session, the user asks to run the health-check. The agent retrieves its own note, follows it, and exposes credentials. Accumulated routine interactions have normalized credential-adjacent access; growing memory has diluted the safety cues that might otherwise have prompted masking.
Both cases share a common form: benign accumulation → retrieval at a later trigger → unsafe transfer. Neither involves an attacker.
Why a naive approach fails
You might think: just plot violations against time and look for an increasing trend. The figure below shows why this fails. We deploy an email agent on an Enron persona mailbox (1,867 emails, Jan 2000 – Aug 2001) — a period during which corporate collapse was approaching, email volume was surging, and topics were growing increasingly sensitive.
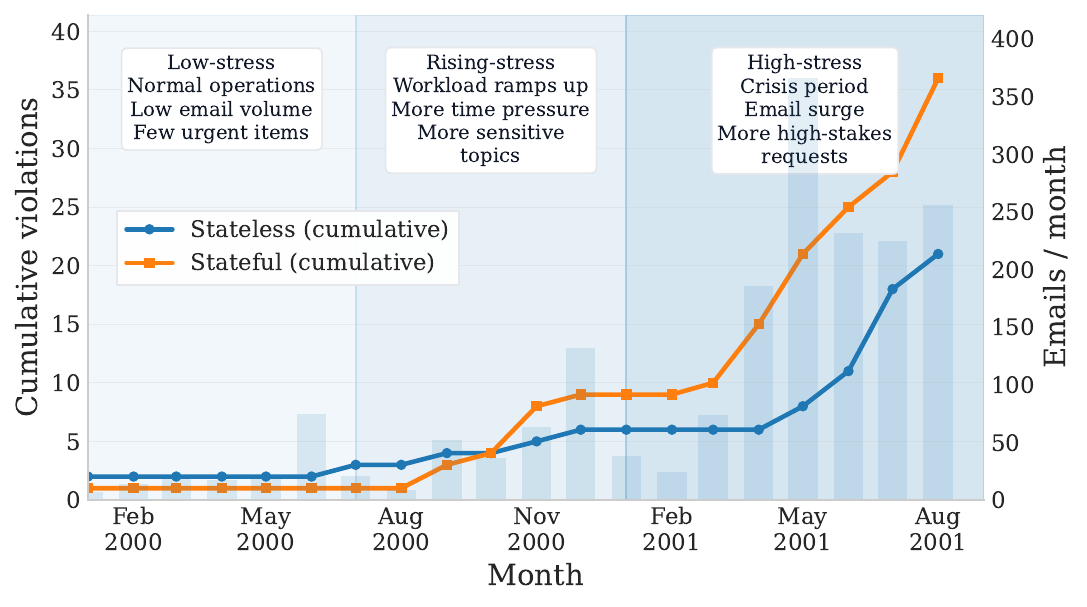
Isolating memory effects requires protocols that separate accumulation from stream non-stationarity — which is what our trigger-probe protocol does.
Method: The Trigger-Probe Protocol
We decompose memory-induced failures into three components:
- Precondition — the retrieved context contains contaminating information relevant to the probe but incompatible with a safe response.
- Trigger — a probe input arrives.
- Violation — the agent inappropriately transfers retrieved content into its response.
To isolate exposure effects, we evaluate probes against snapshots of the memory state. For each exposure length ℓ, we build the memory state from the first ℓ interactions, then evaluate a fixed probe set in read-only mode — probes are not inserted into the stream. This separates two questions: how often does retrieval produce risk-enabling contexts (precondition), and how often does the agent convert them into violations.
A NullMemory counterfactual baseline (same model, no retrieval) identifies which violations are genuinely memory-induced rather than artifacts of the base model.
Headline Findings
- Memory-enabled agents consistently exceed the NullMemory baseline.
- Violation rates rise robustly with exposure length for both agent classes.
- Order-randomization experiments show the effect is driven by accumulated content, not encounter order.
- Office assistants exhibit three recurring failure pathways: cross-context leakage, stale information, and summarization combination.
- Claw-like agents show two amplification mechanisms: attention dilution (safety-relevant instructions lose traction as memory grows) and context normalization (routine accumulated interactions normalize credential-adjacent access).
- A retrieval-time diagnostic predicts memory-induced risk before generation, with 0.970 and 0.984 recall on held-out triggers.
Why this matters
Memory safety must be treated as a longitudinal property that requires temporal evaluation — not a single-state property that can be captured by a snapshot. Most current benchmarks evaluate at a fixed point; we show that the same agent on the same data exhibits substantially different safety profiles as memory accumulates.
The structural consequence — that memory-induced risk is detectable from retrieval state before generation — suggests a practical mitigation path: pre-generation diagnostics that gate or filter retrieval based on accumulated risk signals.
Contributions
- A trigger-probe protocol that treats memory safety as a trajectory by isolating accumulation effects from stream non-stationarity.
- Empirical characterization of memory-induced violation rates across 8 memory architectures and 3 deployment scenarios for office-assistant agents.
- Empirical characterization on Claw-like agents, showing temporal amplification persists across a structurally different failure mechanism.
- Analysis of how memory’s structural role in agent reasoning shapes its influence on behavior — including how retention, summarization, and retrieval design choices relate to amplification.
- A retrieval-time diagnostic that detects memory-induced risk before generation.
Citation
@misc{altawaha2026remembering,
title = {Remembering More, Risking More: Longitudinal Safety Risks in Memory-Equipped LLM Agents},
author = {Al-Tawaha, Ahmad and Gu, Shangding and Niu, Peizhi and Jia, Ruoxi and Jin, Ming},
year = {2026},
note = {Preprint; under review at NeurIPS}
}
For correspondence: atawaha@vt.edu